)
Following the strong wake created by the Fail Whale, Twitter created a life raft in the form of stateless containerized micro services. In just a few years, they’ve scaled to hundreds of teams running thousands of services on tens of thousands of hosts and in hundreds of thousands of containers.
Ian Downes is engineering manager for the compute platform team at Twitter. His team of about 10 engineers and a few other staffers buoys a platform providing container infrastructure to much of the stateless services powering twitter.com and its advertising business. Downes spoke recently at Container World on “Twitter’s Micro Services Architecture: Operational & Technical Challenges.”
When people talk about containerization, he says, it’s often about how it can enable scale and disruption, but that doesn’t interest Downes much.
“What I’m more interested in are scaleable operations — independent of what scale you’re at,” he says. “What happens when you increase in size, number of machines, number of VMs, number of customers, the number of services you’re running? If you double that, or quadruple, does your operational workload double or quadruple along with it, or does it basically stay the same?”
Thanks to concerted efforts in the last few years, Twitter has infrastructure that can scale very suddenly -doubling, if necessary – and, Downes says, has blown through several orders of magnitudes of growth without a corresponding operations burden.
You might wonder where did the Fail Whale go? Truth to be told: It is failed to fail — now becomes a WIN Whale! pic.twitter.com/aWIG9HLN2y
— Fail Whale (@failwhale) May 29, 2014
Early on, Twitter was a monolithic application, made infamous by Fail Whale outages in 2010-2012. The social media company was towed under by events including a cascading bug, the Summer Olympics and the FIFA World Cup. They now run thousands of services for hundreds of teams inside the company, all done on their own infrastructure, their own machines, including tens of thousands of hosts and hundreds of thousands of containers.
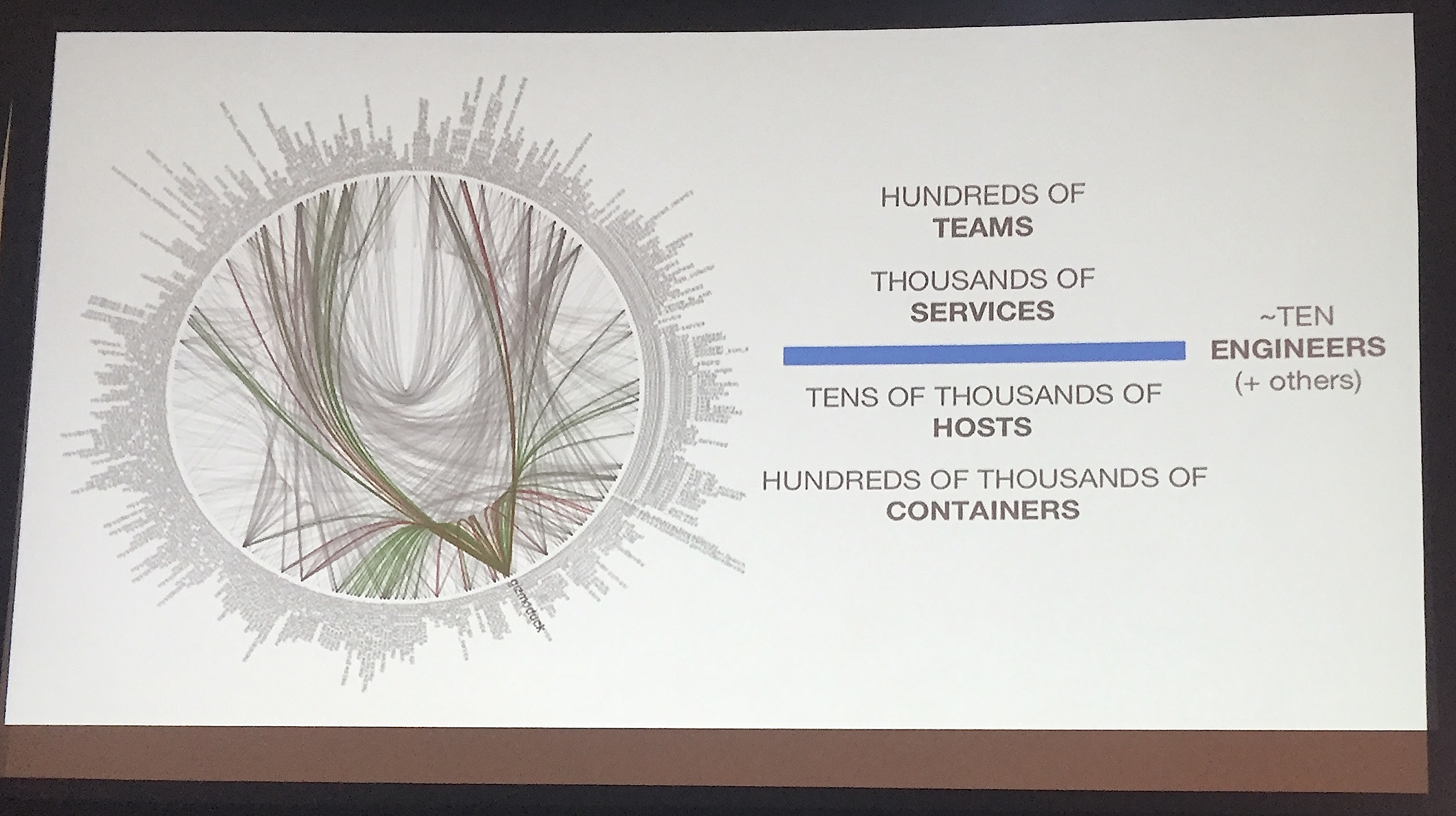
“What’s interesting, though, is that the platform that my team manages that infrastructure and provides that platform for those users with a team of about 10 engineers. That’s a pretty amazing number.”
The journey from a monolithic application to micro services wasn’t a simple one. Before coming to the common platform, each one of those micro services ran their own structure and each ops team had their own way of doing things. Downes likens it to cat herding — customers have habits, are opinionated and want to do things in a particular way. That meant keeping a ratio of 10:1 – 10 customers or 10 machines for every engineer.
“For a platform to be successful at the scale we intended, we had to view customers more like sheep,” he says. The soft-spoken Downes underlines that the analogy isn’t intended in a disparaging way, but simply that, like in his native New Zealand, a whole herd of sheep can be managed with two or three skilled sheepdogs. “It’s all nice and smooth and very low fuss.”
How they did it
It sounds like a tall order, but Downes says the solution is simple: a contract with customers that decouples availability and applications from operations. This contract asks users to architect for individual instances of their application being rescheduled and, in turn, his team promises to keep those services healthy. (A service may have 100 or 1,000 instances that are identical copies of the service, he adds.)
“Obviously, failures still happen,” he says. “It doesn’t matter whether you’re running on virtualized infrastructure or the cloud. You have to architect for it, but that’s not sufficient because it doesn’t give any leeway for operations and we don’t want them to architect and solve their problems in a different way.”

At any point in time, the compute team can schedule instances of applications and move them around inside the cluster. Doing that will keep the service healthy – not running. “Running is not sufficient,” Downes emphasizes. However, his team doesn’t guarantee how many instances will run for each application. If they request to run 100 instances, they may be running fewer (due to failure or rescheduling) but the engineering team also doesn’t guarantee that it won’t exceed the number of instances, either.
“This seems a little strange, but it can happen with partitioning,” he says. For example, when the agent installed on the host running the instance loses connectivity. Because the compute team doesn’t know the state of those instances, they’ll spin up additional ones somewhere else in the cluster, so an application could exceed the number of instances. In general, the number of instances running at any given time doesn’t matter.
The compute team set a target of keeping 95 percent of instances healthy for at least 5 minutes as part of the contract. “We say ‘we won’t take out too much of the service at any given time and we won’t do it too quickly.’

To make it work for customers, there are a few caveats in place. They make it easy for customers to scale without fretting over instances — the more the better. But customers are also required to express how sensitive those instances are to different failure rates.
Downes says it’s a way to chop up instances into groups that can be operated on. He offered an example of 20 distributed across five different racks. If the host goes down, they can lose one out of 20 (only five percent) if the rack goes down, they lose 25 percent of capacity (obviously a large fraction) so they’re encouraged to scale way beyond 20…“It’s good for them, it’s good for failures and it’s good for us.” (In response to a follow-up question, Downes says Twitter uses Apache Aurora Mesos but details were beyond the scope of his 20-minute talk.)

Every operation in the cluster is aware of the contract for each job. “So if we want to migrate something – we actually kill and then restart – we’ll give it five minutes once it becomes healthy before we act on anything that might impact that job again.” One host running 10 different containers, 10 different user loads have to keep track of across all the machines. “This means we can do actions on the cluster without impacting our customers.”
The next question is whether it’s sufficient to enable the compute team to manage the operational work load. The answer: Absolutely. Downes says they can roll an entire 30,000-node cluster running a full production workload — meaning they can reboot those nodes — in 24 hours with zero customer impact. While Downes calls that “aggressive” and not something they regularly do, they have done it for a kernel update and successfully, too. “There was no panic, no fires to put out, no alerts were triggered — we didn’t get a single customer request.”

What’s next: Extreme cat makeover
Downes says the team is exploring whether the contract concept can be taken further. “We see ourselves almost as a public cloud. Other teams inside the company provide machines to us. If those machines fail, we go over the wall and say, ‘Can you give us a machine that’s healthy?’ It’s very much like running in the public cloud in that way.”
He admits that the timing is different — if a host fails and it’s taken it offline they may not get a replacement for a day or two. “We are, in effect, customers. We tell those providers, ‘We don’t care if you need to act on our machines, if it’s at the rack level, just go in and do it.’” For example, the operations team may want to take the top rack switch offline and do some maintenance on it — they’re welcome to without any interference or notice from the compute team.
This means his team has decoupled itself from the infrastructure and decoupled users from the infrastructure. “It’s incredibly powerful, we have a resilient platform that we can poke and prod and perform operations on and it doesn’t affect our users.”

The picture that he painted of a flock of sheep expertly herded by a few dogs isn’t the whole picture, he admits. “The reality is a little different. We have a lot of sheep and a few cats in the mix as well.” The bulk of Twitter’s shared cluster is where the sheep run – the customers who accept that contract run their services there. On the side, running through the same scheduler etc., are the cats. These customers have special requirements — persistent storage services, special hardware requirements, churning, etc. — that don’t fit into the contract but want to take advantage of the orchestration, containerization and tooling.
“The unfortunate thing is that they dominate our operation workload even though they’re only about 15 percent of our cluster capacity,” he says. “In theory, we had a hybrid contract, the ‘cats’ could bring machines into the hybrid cluster and we’ll run them through our infrastructure but you need to maintain the host, update them, etc.”
Those good intentions often go astray, however. And, despite the agreement, Downes and team end up maintaining them. That’s where the yowling begins: “it’s very painful to manage these machines,” Downes says. “Our operations burden is dominated by these special cases.”
Converting those cats into sheep is what they’re working on now. It may entail extending that contract, loosening it — they’ll only restart or reschedule some applications over a few days rather than five minutes. Another solution may be that stateful services have a “best effort restart” on the same host (so customers can reattach to the same storage) or delegating more work to internal teams.
“These are all questions that we’re trying to answer,” Downes says. “We’ve been incredibly successful in scaling up the stateless infrastructure, the next question is whether can we take those existing customers already in the cluster that are causing us this burden and take on new customers while maintaining operational scalability.”
Stay tuned.
Cover Photo // CC BY NC
- OpenStack Homebrew Club: Meet the sausage cloud - July 31, 2019
- Building a virtuous circle with open infrastructure: Inclusive, global, adaptable - July 30, 2019
- Using Istio’s Mixer for network request caching: What’s next - July 22, 2019










