)
Testing cloud-native micro-services is critical for creating robust, reliable and scalable applications. It is crucial to have an automated CI pipeline that tests the main branch of the application and creates a checkpoint for pull requests from other branches. There are well-defined and established levels of testing in the industry; however, in this tutorial we’ll dive into testing for cloud-native micro-services.
Before getting into the levels of testing, let’s consider creating a sample API. This API will be created with the perspective of organizing, retrieving, and analyzing information on books in a library. A sample book-server was designed with cloudnative microservice architecture in mind and will be used for defining different levels of test in this section.
Note: The source code of the book-server API can be found here: https://gitlab.com/TrainingByPackt/book-server.
Keeping the micro-service architecture in perspective, we need to design and implement self-sufficient services for accomplishing business needs. To that end, we’ll create a micro-service that works as a REST API to interact with the book information. We do not need to consider how book information is stored in a database, since it should be a separate service in the architecture. In other words, we need to create a REST API server that works with any SQL-capable database and design it to be compatible with other types of databases in the future.
Before exploring the details of book-server, let’s take a look at the structure of the repository by using the tree command. With the following command, all of the files and folders are listed, except for the vendor folder, where the source code of Go dependencies are kept:
tree -I vendor –U
You can view the files and folder in the following output:
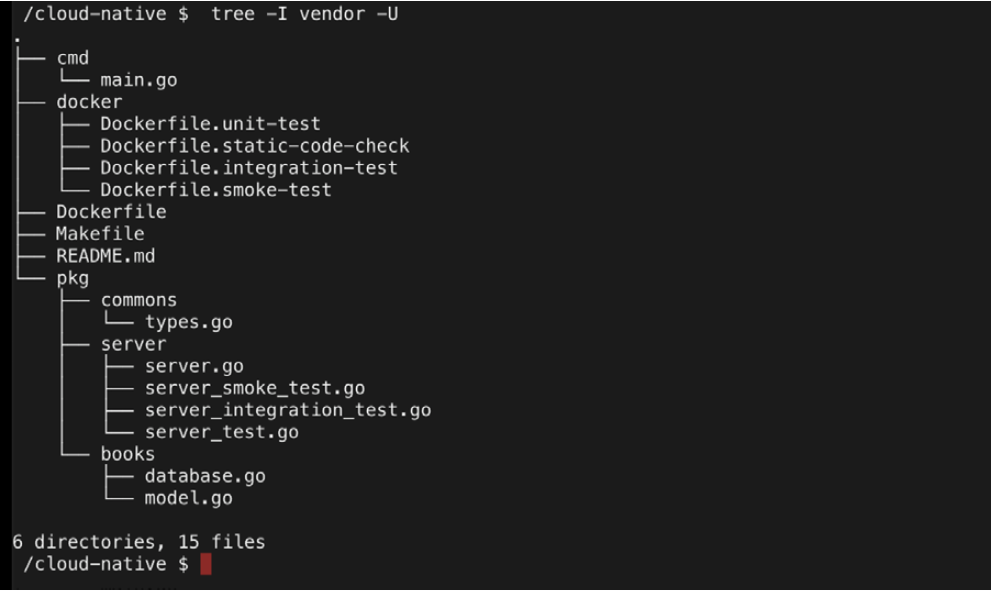
By following the best practices in Go development, the book-server is structured as follows:
- The cmd folder includes main.go, which creates the executable for the bookserver
- The docker folder includes Dockerfiles that will be used for different testing levels such as static code check, unit test, smoke test, and integration test
- Dockerfile is the container definition that’s used for building book-server
- Makefile contains the commands to test and build the repository
- README.md includes documentation on the repository
- The pkg folder consists of the source code of the book-server
- pkg/books defines the database and book interfaces for extending book-server
- pkg/commons defines the option types that are used within book-server
- pkg/server consists of the HTTP REST API code and related tests
For our API, book-server is a Go REST API micro-service that connects to a database and serves information about books. In the cmd/main.go file, it can be seen that the service only works with three parameters:
- Log level
- HTTP port
- Database address
In the following init function, in main.go, these three parameters are defined as command-line arguments as log-level, port, and db:
func init() { pflag.StringVar(&options.ServerPort, "port", "8080", "Server port for listening REST calls") pflag.StringVar(&options.DatabaseAddress, "db", "", "Database instance") pflag.StringVar(&options.LogLevel, "log-level", "info", "Log level, options are panic, fatal, error, warning, info and debug")
It is expected that you should have different levels of logging in microservices so that you can debug services running in production better. In addition, ports and database addresses should be configured on the fly, since these should be the concerns of the users, not developers.
In the pkg/books/model.go file, Book is defined, and an interface for book database, namely BookDatabase, is provided. It is crucial for micro-services to work with interfaces instead of implementations, since interfaces enable plug-and-play capability and create an open architecture. You can see how book and BookDatabase are defined in the following snippet:
type Book struct {
ISBN string
Title string
Author string
}
type BookDatabase interface {
GetBooks() ([]Book, error)
Initialize() error
}
Note: The code files for this section can be found here: https://bit.ly/2S92tbr.
In the pkg/books/database.go file, an SQL-capable BookDatabase implementation is developed as SQLBookDatabase. This implementation enables the book-server to work with any SQL capable database. The Initialize and GetBooks methods could be checked for how SQL primitives are utilized to interact with the database. In the following code fragment, the GetBooks and Initialize implementations are included, along with their SQL usages:
func (sbd SQLBookDatabase) GetBooks() ([]Book, error) {
books := make([]Book, 0)
rows, err := sbd.db.Query('SELECT * FROM books')
//[…]
return books, nil
}
func (sbd SQLBookDatabase) Initialize() error {
var schema = 'CREATE TABLE books (isbn text, title text, author
text);'
//[…]
return nil
}
Finally, in the server/server.go file, an HTTP REST API server is defined and connected to a port for serving incoming requests. Basically, this server implementation interacts with the BookDatabase interface and returns the responses according to HTTP results.
In the following fragment of the Start function in server.go, endpoints are defined and then the server starts to listen on the port for incoming requests:
func (r *REST) Start() {
//[…]
r.router.GET("/ping", r.pingHandler)
r.router.GET("/v1/init", r.initBooks)
r.router.GET("/v1/books", r.booksHandler)
r.server = &http.Server{Addr: ":" + r.port, Handler: r.router}
//[…]
err := r.server.ListenAndServe()
//[…]
}
Note: The complete code can be found here: https://bit.ly/2Cm9Mag.
Static code analysis
In the preceding section, a cloud-native micro-service application, namely bookserver, was presented, along with its important features. In the next section, we will begin with static code analysis so that we can test this application comprehensively.
Reading and finding flaws in code is cumbersome and requires many engineering hours. It helps to use automated code analysis tools that analyze the code and find potential problems. It’s a crucial step and should factored into the very first stages of the CI pipeline. Static code analysis is essential because correctly working code with the wrong style will cause more damage than non-functional code.
It’s beneficial for all levels of developers and quality teams to follow standard guidelines in the programming languages and create their styles and templates only if necessary. There are many static code analyzers available on the market as services or open source, including:
- Pylint for Python
- FindBugs for Java
- SonarQube for multiple languages and custom integrations
- The IBM Security AppScan Standard for security checks and data breaches
- JSHint for JavaScript
However, when choosing a static code analyzer for a cloud-native micro-service, the following three points should be considered:
- The best tool for the language: It is common to develop micro-services in different programming languages; therefore, you should select the best static code analyzer for the language rather than employing one-size-fits-all solutions.
- Scalability of the analyzer: Similar to cloud-native applications, tools in software development should also be scalable. Therefore, select only those analyzers that can run in containers.
- Configurability: Static code analyzers are configured to run and find the most widely accepted errors and flaws in the source code. However, the analyzer should also be configured to different levels of checks, skipping some checks or adding some more rules to check.
Exercise: Performing static code analysis in containers
In this exercise, a static code analyzer for the book-server application will be run in a Docker container. Static code analysis will check for the source code of book-server and list the problematic cases, such as not checking the error returned by functions in Go. To complete this exercise, the following steps have to be executed:
Note: All tests and build steps are executed for the book-server application in the root folder. The source code of the book-server is available on GitLab: https://gitlab.com/TrainingByPackt/book-server. The code file for this exercise can be found here: https://bit.ly/2EtB0Ny.
1. Open the docker/Dockerfile.static-code-check file from the GitlLab interface and check the container definition for the static code analysis:
FROM golangci/golangci-lint
ADD . /go/src/gitlab.com/onuryilmaz/book-server
WORKDIR /go/src/gitlab.com/onuryilmaz/book-server
RUN golangci-lint run ./…
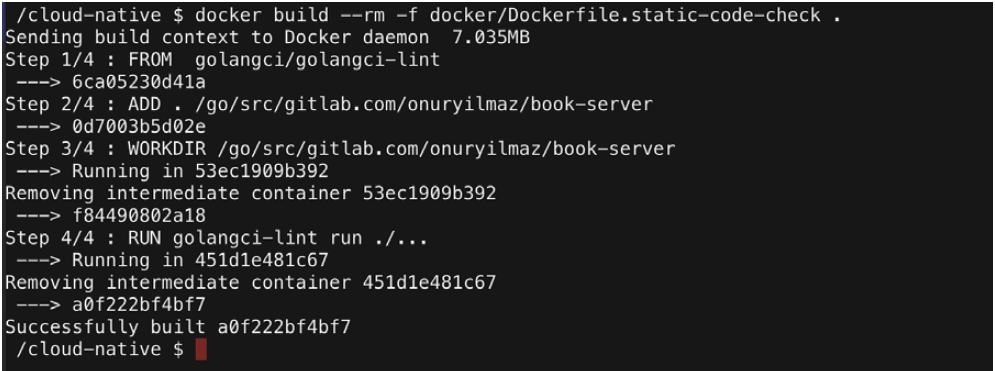
2. Build the container in the root directory of book-server by running the following code:
docker build --rm -f docker/Dockerfile.static-code-check .
In the preceding file, the golangci/golangci-lint image is used as the static code analysis environment and the book-server code is copied. Finally, golangci-lint is run for all folders to find flaws in the source code.
The following output is obtained once the preceding code is run with no errors, with a “successfully built” message at the end:
3. Change the Initialize function in pkg/books/database.go as follows by removing error checks in the SQL statements:
func (sbd SQLBookDatabase) Initialize() error {
var schema = 'CREATE TABLE books (isbn text, title text, author
text);'
sbd.db.Exec(schema)
var firstBooks = 'INSERT INTO books …'
sbd.db.Exec(firstBooks)
return nil
}
With the modified Initialize function, the responses of the sbd.db.Exec methods are not checked. If these executions fail with some errors, these return values are not controlled and not sent back to caller functions. It’s a bad practice and a common mistake in programming that’s mostly caused by the assumption that the code will always run successfully.
4. Run the following command, as we did in step two:
docker build --rm -f docker/Dockerfile.static-code-check .
Since we had modified the code is step three, we should see a failure as a result of this command, as shown in the following screenshot:
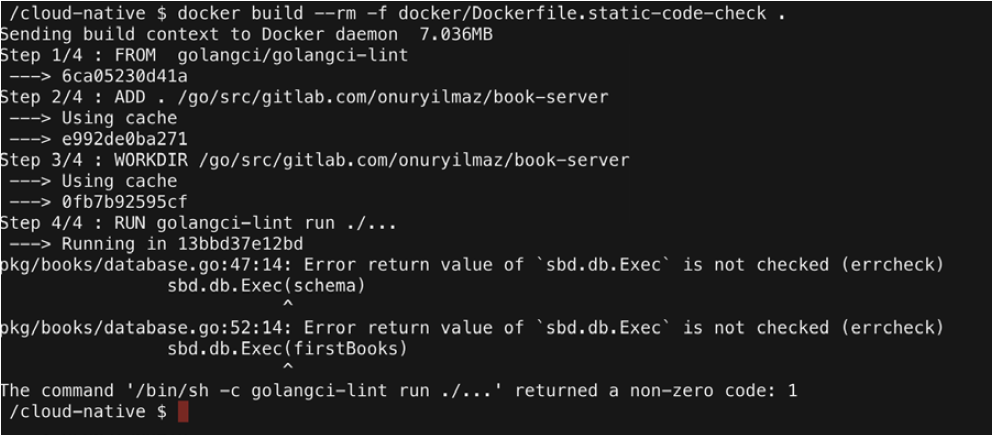
As we can see, errcheck errors are expected, since we’re not checking for the errors during SQL executions.
Revert the code for the Initialize function to the original, with error checks where static code analysis successfully completed; otherwise, the static code analysis step will always fail in the pipeline and the further steps will never run.
Hope you enjoyed reading this article. If you want to learn more about continuous integration and delivery, check out the online course “Cloud-Native Continuous Integration and Delivery.” Developed by author Onur Yilmaz, the class begins with an introduction to cloud-native concept, teaching participants skills to create a continuous integration and delivery environment for your applications and deploy them using tools such as Kubernetes and Docker.
This content was provided by Packt Pub.
- Demystifying Confidential Containers with a Live Kata Containers Demo - July 13, 2023
- OpenInfra Summit Vancouver Recap: 50 things You Need to Know - June 16, 2023
- Congratulations to the 2023 Superuser Awards Winner: Bloomberg - June 13, 2023










