)
VANCOUVER — The European Organization for Nuclear Research, known as CERN, is on a mission to unravel the mysteries of the universe.
Driven by the demand to support research at the world’s largest particle collider, the CERN IT department decided in 2012 to build an agile infrastructure centered around an OpenStack- based private cloud. CERN provides several facilities and resources to scientists all around the world, including compute and storage resources, for their fundamental research.
Internally, CERN’s data center provides roughly 20 to 25 percent of these resources, says Arne Wiebalck, computing engineer. The analysis is done in a worldwide distributed grid with 170 data centers on about 800,000 cores and a total 900 petabytes of data on disk on tape. Some 90 percent of the CERN resources are delivered on top of OpenStack.
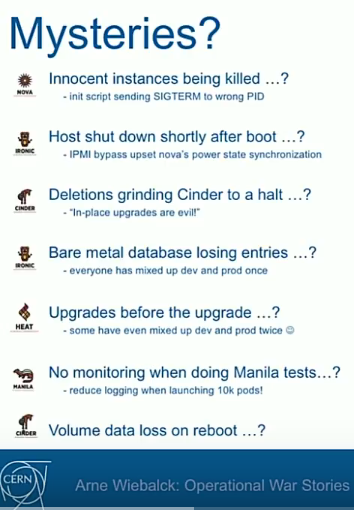
Running OpenStack in production has also lead to some mysteries, challenges setbacks and achievements, much like those faced by its researchers Wiebalck says.
One of these head-scratchers was the baffling case of innocent instances being killed randomly, VMs “just disappearing.” The culprit was a random independent service that was supposed to remember which PIDs to kill — but instead just killed randomly here and there. “It took us quite a while to identify the murderer,” he adds.
Then there were hosts shutting down right after boot, deletions grinding Cinder to a halt and the bare metal database losing entries.
Challenges included scaling a booming service — more than 300,000 cores over 9,000 hypervisors spanning over 4,000 projects — continuous upgrades, staff turnover and bridging the physical-to-virtual performance gap.

Fortunately the CERN team can count a vast number of achievements, too. In addition to the numbers cited above, they include deployment across two data centers, migration of thousands of VMS due, two million requests handled by a Magnum Kubernetes cluster and many contributions upstream.
Catch his entire talk below or on the OSF’s YouTube channel.
- OpenStack Homebrew Club: Meet the sausage cloud - July 31, 2019
- Building a virtuous circle with open infrastructure: Inclusive, global, adaptable - July 30, 2019
- Using Istio’s Mixer for network request caching: What’s next - July 22, 2019










