)
This article originally appeared on JAVACRUFT. James is the technical lead of the Ubuntu server team. You should follow him on Twitter.
In the run up to the OpenStack summit in Atlanta, the Ubuntu Server team had it’s first opportunity to test OpenStack at real scale.
AMD made available 10 SeaMicro 15000 chassis in one of their test labs. Each chassis has 64, 4 core, 2 thread (8 logical cores), 32GB RAM servers with 500G storage attached via a storage fabric controller – creating the potential to scale an OpenStack deployment to a large number of compute nodes in a small rack footprint.
As you would expect, we chose the best tools for deploying OpenStack:
- MAAS – Metal-as-a-Service, providing commissioning and provisioning of servers.
- Juju – The service orchestration for Ubuntu, which we use to deploy OpenStack on Ubuntu using the OpenStack charms.
- OpenStack Icehouse on Ubuntu 14.04 LTS.
- CirrOS – a small footprint linux based Cloud OS
MAAS has native support for enlisting a full SeaMicro 15k chassis in a single command – all you have to do is provide it with the MAC address of the chassis controller and a username and password. A few minutes later, all servers in the chassis will be enlisted into MAAS ready for commissioning and deployment:
maas local node-group probe-and-enlist-hardware
nodegroup model=seamicro15k mac=00:21:53:13:0e:80
username=admin password=password power_control=restapi2Juju has been the Ubuntu Server teams preferred method for deploying OpenStack on Ubuntu for as long as I can remember; Juju uses Charms to encapsulate the knowledge of how to deploy each part of OpenStack (a service) and how each service relates to each other – an example would include how Glance relates to MySQL for database storage, Keystone for authentication and authorization and (optionally) Ceph for actual image storage.
Using the charms and Juju, it’s possible to deploy complex OpenStack topologies using bundles, a yaml format for describing how to deploy a set of charms in a given configuration – take a look at the OpenStack bundle we used for this test to get a feel for how this works.
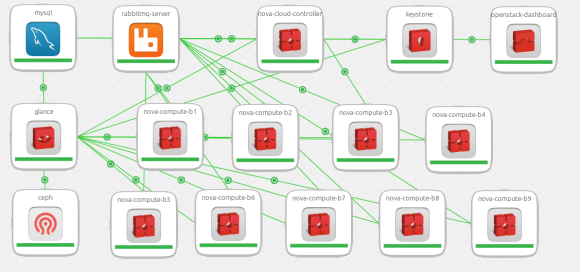
Starting out small(ish)
All ten chassis were not all available from the outset of testing, so we started off with two chassis of servers to test and validate that everything was working as designed. With 128 physical servers, we were able to put together a Neutron based OpenStack deployment with the following services:
- 1 Juju bootstrap node (used by Juju to control the environment), Ganglia Master server
- 1 Cloud Controller server
- 1 MySQL database server
- 1 RabbitMQ messaging server
- 1 Keystone server
- 1 Glance server
- 3 Ceph storage servers
- 1 Neutron Gateway network forwarding server
- 118 Compute servers
We described this deployment using a Juju bundle, and used the juju-deployer tool to bootstrap and deploy the bundle to the MAAS environment controlling the two chassis. Total deployment time for the two chassis to the point of a OpenStack cloud that was usable was around 35 minutes.
At this point we created 500 tenants in the cloud, each with its own private network (using Neutron), connected to the outside world via a shared public network. The immediate impact of doing this is that Neutron creates dnsmasq instances, Open vSwitch ports and associated network namespaces on the Neutron Gateway data forwarding server – seeing this many instances of dnsmasq on a single server is impressive – and the server dealt with the load just fine!
Next we started creating instances; we looked at using Rally for this test, but it does not currently support using Neutron for instance creation testing, so we went with a simple shell script that created batches of servers (we used a batch size of 100 instances) and then waited for them to reach the ACTIVE state. We used the CirrOS cloud image (developed and maintained by the Ubuntu Server teams’ very own Scott Moser) with a custom Nova flavor with only 64 MB of RAM.
We immediately hit our first bottleneck – by default, the Nova daemons on the Cloud Controller server will spawn sub-processes equivalent to the number of cores that the server has. Neutron does not do this and we started seeing timeouts on the Nova Compute nodes waiting for VIF creation to complete. Fortunately Neutron in Icehouse has the ability to configure worker threads, so we updated the nova-cloud-controller charm to set this configuration to a sensible default, and provide users of the charm with a configuration option to tweak this setting. By default, Neutron is configured to match what Nova does, 1 process per core – using the charm configuration this can be scaled up using a simple multiplier – we went for 10 on the Cloud Controller node (80 neutron-server processes, 80 nova-api processes, 80 nova-conductor processes). This allowed us to resolve the VIF creation timeout issue we hit in Nova.
At around 170 instances per compute server, we hit our next bottleneck; the Neutron agent status on compute nodes started to flap, with agents being marked down as instances were being created. After some investigation, it turned out that the time required to parse and then update the iptables firewall rules at this instance density took longer than the default agent timeout – hence why agents kept dropping out from Neutrons perspective. This resulted in virtual interface (VIF) creation timing out and we started to see instance activation failures when trying to create more that a few instances in parallel. Without an immediate fix for this issue (see bug 1314189), we took the decision to turn Neutron security groups off in the deployment and run without any VIF level iptables security. This was applied using the nova-compute charm we were using, but is obviously not something that will make it back into the official charm in the Juju charm store.
With the workaround on the Compute servers and we were able to create 27,000 instances on the 118 compute nodes. The API call times to create instances from the testing endpoint remained pretty stable during this test, however as the Nova Compute servers got heavily loaded, the amount of time taken for all instances to reach the ACTIVE state did increase:
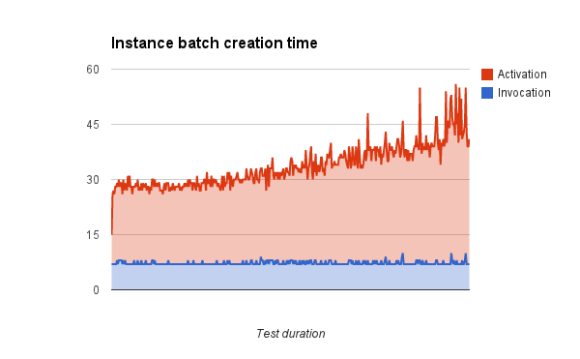
Doubling up
At this point AMD had another two chassis racked and ready for use so we tore down the existing two chassis, updated the bundle to target compute services at the two new chassis and re-deployed the environment. With a total of 256 servers being provisioned in parallel, the servers were up and running within about 60 minutes, however we hit our first bottleneck in Juju.
The OpenStack charm bundle we use has a) quite a few services and b) a-lot of relations between services – Juju was able to deploy the initial services just fine, however when the relations where added, the load on the Juju bootstrap node went very high and the Juju state service on this node started to throw a larger number of errors and became unresponsive – this has been reported back to the Juju core development team (see bug 1318366).
We worked around this bottleneck by bringing up the original two chassis in full, and then adding each new chassis in series to avoid overloading the Juju state server in the same way. This obviously takes longer (about 35 minutes per chassis) but did allow us to deploy a larger cloud with an extra 128 compute nodes, bringing the total number of compute nodes to 246 (118+128).
And then we hit our next bottleneck…
By default, the RabbitMQ packaging in Ubuntu does not explicitly set a file descriptor ulimit so it picks up the Ubuntu defaults – which are 1024 (soft) and 4096 (hard). With 256 servers in the deployment, RabbitMQ hits this limit on concurrent connections and stops accepting new ones. Fortunately it’s possible to raise this limit in /etc/default/rabbitmq-server – and as we were deployed using the rabbitmq-server charm, we were able to update the charm to raise this limit to something sensible (64k) and push that change into the running environment. RabbitMQ restarted, problem solved.
With the 4 chassis in place, we were able to scale up to 55,000 instances.
Ganglia was letting us know that load on the Nova Cloud Controller during instance setup was extremely high (15-20), so we decided at this point to add another unit to this service:
juju add-unit nova-cloud-controllerand within 15 minutes we had another Cloud Controller server up and running, automatically configured for load balancing of API requests with the existing server and sharing the load for RPC calls via RabbitMQ. Load dropped, instance setup time decreased, instance creation throughput increased, problem solved.
Whilst we were working through these issues and performing the instance creation, AMD had another two chassis (6 & 7) racked, so we brought them into the deployment adding another 128 compute nodes to the cloud bringing the total to 374.
And then things exploded…
The number of instances that can be created in parallel is driven by two factors – 1) the number of compute nodes and 2) the number of workers across the Nova Cloud Controller servers. However, with six chassis in place, we were not able to increase the parallel instance creation rate as much as we wanted to without getting connection resets between Neutron (on the Cloud Controllers) and the RabbitMQ broker.
The learning from this is that Neutron+Nova makes for an extremely noisy OpenStack deployment from a messaging perspective, and a single RabbitMQ server appeared to not be able to deal with this load. This resulted in a large number of instance creation failures so we stopped testing and had a re-think.
A change in direction
After the failure we saw in the existing deployment design, and with more chassis still being racked by our friends at AMD, we still wanted to see how far we could push things; however with Neutron in the design, we could not realistically get past 5-6 chassis of servers, so we took the decision to remove Neutron from the cloud design and run with just Nova networking.
Fortunately this is a simple change to make when deploying OpenStack using charms as the nova-cloud-controller charm has a single configuration option to allow Neutron and Nova networkings to be configured. After tearing down and re-provisioning the 6 chassis:
juju destroy-enviroment maas
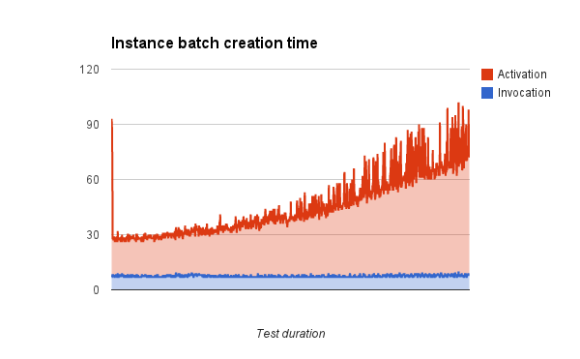
juju-deployer --bootstrap -c seamicro.yaml -d trusty-icehouseWith the revised configuration, we were able to create instances in batches of 100 at a respectable throughput of initially 4.5/sec – although this did degrade as load on compute servers went higher. This allowed us to hit 75,000 running instances (with no failures) in 6hrs 33 mins, pushing through to 100,000 instances in 10hrs 49mins – again with no failures.
As we saw in the smaller test, the API invocation time was fairly constant throughout the test, with the total provisioning time through to ACTIVE state increasing due to loading on the compute nodes:
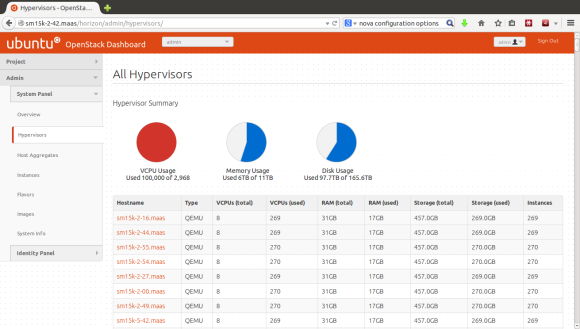
Status check
OK – so we are now running an OpenStack Cloud on Ubuntu 14.04 across 6 seamicro chassis (1,2,3,5,6,7 – 4 comes later) – a total of 384 servers (give or take one or two which would not provision). The cumulative load across the cloud at this point was pretty impressive – Ganglia does a pretty good job at charting this:
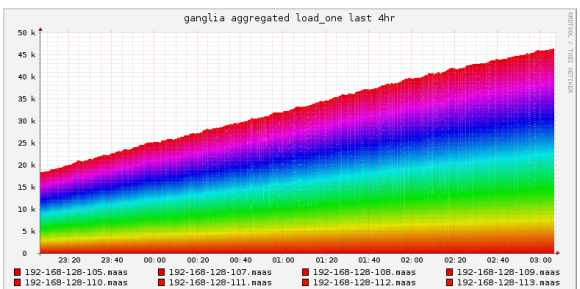
AMD had two more chassis (8 & 9) in the racks which we had enlisted and commissioned, so we pulled them into the deployment as well; This did take some time – Juju was grinding pretty badly at this point and just running ‘juju add-unit -n 63 nova-compute-b6′ was taking 30 minutes to complete (reported upstream – see bug 1317909).
After a couple of hours we had another ~128 servers in the deployment, so we pushed on and created some more instances through to the 150,000 mark – as the instances where landing on the servers on the 2 new chassis, the load on the individual servers did increase more rapidly so instance creation throughput did slow down faster but the cloud managed the load.
Tipping point?
Prior to starting testing at any scale, we had some issues with one of the chassis (4) which AMD had resolved during testing, so we shoved that back into the cloud as well; after ensuring that the 64 extra servers where reporting correctly to Nova, we started creating instances again.
However, the instances kept scheduling onto the servers in the previous two chassis we added (8 & 9) with the new nodes not getting any instances. It turned out that the servers in chassis 8 & 9 where AMD based servers with twice the memory capacity; by default, Nova does not look at VCPU usage when making scheduling decisions, so as these 128 servers had more remaining memory capacity that the 64 new servers in chassis 4, they were still being targeted for instances.
Unfortunately I’d hopped onto the plane from Austin to Atlanta for a few hours so I did not notice this – and we hit our first 9 instance failures. The 128 servers in Chassis 8 and 9 ended up with nearly 400 instances each – severely over-committing on CPU resources.
A few tweaks to the scheduler configuration, specifically turning on the CoreFilter and setting the over commit at x 32, applied to the Cloud Controller nodes using the Juju charm, and instances started to land on the servers in chassis 4. This seems like a sane thing to do by default, so we will add this to the nova-cloud-controller charm with a configuration knob to allow the over commit to be altered.
At the end of the day we had 168,000 instances running on the cloud – this may have got some coverage during the OpenStack summit….
The last word
Having access to this many real servers allowed us to exercise OpenStack, Juju, MAAS and our reference Charm configurations in a way that we have not been able undertake before. Exercising infrastructure management tools and configurations at this scale really helps shake out the scale pinch points – in this test we specifically addressed:
- Worker thread configuration in the nova-cloud-controller charm
- Bumping open file descriptor ulimits in the rabbitmq-server charm enabled greater concurrent connections
- Tweaking the maximum number of mysql connections via charm configuration
- Ensuring that the CoreFilter is enabled to avoid potential extreme overcommit on nova-compute nodes.
There where a few things we could not address during the testing for which we had to find workarounds:
- Scaling a Neutron base cloud past more than 256 physical servers
- High instance density on nova-compute nodes with Neutron security groups enabled.
- High relation creation concurrency in the Juju state server causing failures and poor performance from the juju command line tool.
We have some changes in the pipeline to the nova-cloud-controller and nova-compute charms to make it easier to split Neutron services onto different underlying messaging and database services. This will allow the messaging load to be spread across different message brokers, which should allow us to scale a Neutron based OpenStack cloud to a much higher level than we achieved during this testing. We did find a number of other smaller niggles related to scalability – checkout the full list of reported bugs.
And finally some thanks:
- Blake Rouse for doing the enablement work for the SeaMicro chassis and getting us up and running at the start of the test.
- Ryan Harper for kicking off the initial bundle configuration development and testing approach (whilst I was taking a break- thanks!) and shaking out the initial kinks.
- Scott Moser for his enviable scripting skills which made managing so many servers a whole lot easier – MAAS has a great CLI – and for writing CirrOS.
- Michael Partridge and his team at AMD for getting so many servers racked and stacked in such a short period of time.
- All of the developers who contribute to OpenStack, MAAS and Juju!
.. you are all completely awesome!
Image credit: "Expanded aluminum I" by José Sáez
- How We Scaled OpenStack to Launch 168,000 Cloud Instances - June 27, 2014










