)
As part of the recent OpenStack summit in Austin, the Scientific Working group was established looking into how scientific organisations can best make use of OpenStack clouds.
During our discussions with more than 70 people (etherpad), we concluded on four top areas to look at and started to analyze the approaches and common needs.
The areas were:
- Parallel file system support in Manila. There are a number of file systems supported by Manila but many High Performance Computing sites (HPC) use Lustre which is focussed on the needs of the HPC user community.
- Bare metal management looking at how to deploy bare metal for the maximum performance within the OpenStack frameworks for identity, quota and networking. This team will work on understanding additional needs with the OpenStack Ironic project.
- Accounting covering the wide range of needs to track usage of resources and showback/chargeback to the appropriate user communities.
- Stories is addressing how we collect requirements from the scientific use cases and work with the OpenStack community teams, such as the Product working group, to include these into the development roadmaps along with defining reference architectures on how to cover common use cases such as high performance or high throughput computing clouds in the scientific domain.
Most of the applications run at CERN are high throughput, embarrassingly parallel applications. Simulation and analysis of the collisions such as in the LHC can be farmed to different compute resources with each event being handled independently and no need for fast interconnects. While the working group will cover all the areas (and some outside this list), our focus is on accounting (3).
Given limited time available, it was not possible for each of the interested members of the accounting team to explain their environment. This blog is intended to provide the details of the CERN cloud usage, the approach to resource management and some areas where OpenStack could provide additional function to improve the way we manage the accounting process. Within the Scientific Working group, these stories will be refined and reviewed to produce specifications and identify the potential communities who could start on the development.
##CERN Pledges
The CERN cloud provides computing resources for the Large Hadron Collider and other experiments. The cloud is currently around 160,000 cores in total spread across two data centres in Geneva and Budapest. Resources are managed world wide with the World Wide Computing LHC Grid which executes over 2 million jobs per day. Compute resources in the WLCG are allocated via a pledge model. Rather than direct funding from the experiments or WLCG, the sites, supported by their government agencies, commit to provide compute capacity and storage for a period of time as a pledge and these are recorded in the REBUS system. These are then made available using a variety of middleware technologies.
Given the allocation of resources across 100s of sites, the experiments then select the appropriate models to place their workloads at each site according to compute/storage/networking capabilities. Some sites will be suitable for simulation of collisions (high CPU, low storage and network). Others would provide archival storage and significant storage IOPS for more data intensive applications. For storage, the pledges are made in capacity on disk and tape. The compute resource capacity is pledges in Kilo-HepSpec06 units, abbreviated to kHS06 (based on a subset of the Spec 2006 benchmark) that allows faster processors to be given a higher weight in the pledge compared to slower ones (as High Energy Physics computing is an embarrassingly parallel high throughput computing problem).
The pledges are reviewed on a regular basis to check the requests are consistent with the experiments’ computing models, the allocated resources are being used efficiently and the pledges are compatible with the requests.
Within the WLCG, CERN provides the Tier-0 resources for the safe keeping of the raw data and performs the first pass at reconstructing the raw data into meaningful information. The Tier-0 distributes the raw data and the reconstructed output to Tier 1s, and reprocesses data when the LHC is not running.
The purchases for the Tier-0 pledge for compute is translated into a formal procurement process. Given the annual orders exceed 750 KCHF, the process requires a formal procedure:
- A market survey to determine which companies in the CERN member states could reply to requests in general areas such as compute servers or disk storage. Typical criteria would be the size of the company, the level of certification with component vendors and offering products in the relevant area (such as industry standard servers)
- A tender which specifies the technical specifications and quantity for which an offer is required. These are adjudicated on the lowest cost compliant with specifications criteria. Cost in this case is defined as the cost of the material over 3 years including warranty, power, rack and network infrastructure needed. The quantity is specified in terms of kHS06 with 2GB/core and 20GB storage/core which means that the suppliers are free to try different combinations of top bin processors which may be a little more expensive or lower performing ones which would then require more total memory and storage. Equally, the choice of motherboard components has significant flexibility within the required features such as 19” rack compatible and enterprise quality drives. The typical winning configurations recently have been white box manufacturers.
- Following testing of the proposed systems to ensure compliance, an order is placed with several suppliers, the machines manufactured, delivered, racked-up and burnt it using a set of high load stress tests to identify issues such as cooling or firmware problems.
Typical volumes are around 2,000 servers a year in one or two rounds of procurement. The process from start to delivered capacity takes around 280 days so bulk purchases are needed followed by allocation to users rather than ordering on request. If there are issues found, this process can take significantly longer.
|
Step
|
Time (Days)
|
Elapsed (Days)
|
|
User expresses requirement
|
|
0
|
|
Market Survey prepared
|
15
|
15
|
|
Market Survey for possible vendors
|
30
|
45
|
|
Specifications prepared
|
15
|
60
|
|
Vendor responses
|
30
|
90
|
|
Test systems evaluated
|
30
|
120
|
|
Offers adjudicated
|
10
|
130
|
|
Finance committee
|
30
|
160
|
|
Hardware delivered
|
90
|
250
|
|
Burn in and acceptance
|
30 days typical with 380 worst
case
|
280
|
|
Total
|
|
280+ Days
|
Given the time the process takes, there are only one to two procurement processes run per year. This means that a continuous delivery model cannot be used and therefore there is a need for capacity planning on an annual basis and to find approaches to use the resources before they are allocated out to their final purpose.
Physical Infrastructure
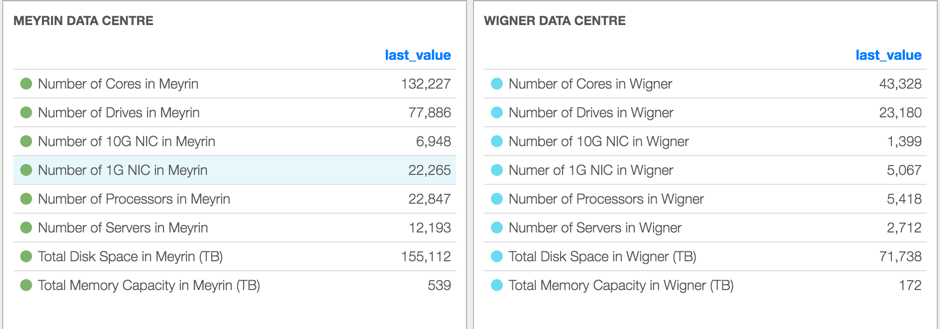
CERN manages two
data centres in Meyrin, Geneva and Wigner, Budapest. The full data is available at the
CERN data centre overview page. When hardware is procured, the final destination is defined as part of the order according to rack space, cooling and electrical availability.
While the installations in Budapest are new installations, some of the Geneva installations involve replacing old hardware. We typically retire hardware between 4 and 5 years old when the CPU power/watt is significantly better with new purchases and the hardware repair costs for new equipment are more predictable and sustainable.
Within the Geneva centre, there are two significant areas, physics and redundant power. Physics power has a single power source which is expected to fail in the event of an electricity cut lasting beyond the few minutes supported by the battery units. The redundant power area is backed by diesels. The Wigner centre is entirely redundant.
Lifecycle
With an annual procurement cycle with 2-3 vendors per cycle, each one with their own optimisations to arrive at the lowest cost for the specifications, the hardware is highly heterogeneous. This has a significant benefit when there are issues, such as disk firmware or BMC controllers, that lead to delays in one of the deliveries being accepted, so the remaining hardware can be made available to experiments.
However, we run the machines for the 3 year warranty and then some additional years on minimal repairs (i.e. simple parts are replaced with components from servers of the same series), we have around 15-20 different hardware configurations for compute servers active in the centre at any time. There are variations in the specifications (as technologies such as SSDs and 10Gb Ethernet became commodity, the new tenders needed these) and those between vendor responses for the same specifications (e.g. slower memory or different processor models).
These combinations do mean that offering standard flavors for each hardware complication would be very confusing for the users, given that there is no easy way for a user to know if resources are available in a particular flavor except to try to create a VM with that flavor.
Given new hardware deliveries and limited space, there are equivalent retirement campaigns. The aim is to replace the older hardware by more efficient newer boxes that can deliver more HS06 within the same power/cooling envelope. The process to empty machines depends on the workloads running on the servers. Batch workloads generally finish within a couple of weeks so setting the servers to no longer accept new work just before the retirements is sufficient. For servers and personal build/test machines, we aim to migrate the workloads to capacity on new servers. This operation is increasingly being performed using live migration and MPLS to extend the broadcast domains for networks to the new capacity.
Projects and Quota
All new users are allocated a project, “Personal XXXX” where XXXX is their CERN account when they subscribe to the CERN cloud service through the CERN resource portal. The CERN resource portal is the entry point to subscribe to the many services available from the central IT department and for users to list their currently active subscriptions and allocations. The personal projects have a minimal quota for a few cores and GBs of block storage so that users can easily follow the tutorial steps on using the cloud and create simple VMs for their own needs. The default image set is available on personal projects along with the standard ‘m’ flavors which are similar to the ones on AWS.
Shared projects can also be requested for activities which are related to an experiment or department. For these resources, a list of people can be defined as administrators (through CERN’s group management system e-groups) and a quota for cores, memory and disk space requested. Additional flavors can also be asked for according to particular needs such as the CERNVM flavors with a small system disk and a large ephemeral one.
The project requests go through a manual approval process, being reviewed by the IT resource management to check the request against the pledge and the available resources. An adjustment of the share of the central batch farm is also made so that the sum of resources for an experiment continues to be within the pledge.
Once the resource request has been manually approved, the ticket is then passed to the cloud team for execution. Rundeck provides us with a simple tool for performing high privilege operations with good logging and recovery. This is used in many of our workflows such as hardware repair. The Rundeck procedure reads the quota settings from the ticket and executes the appropriate project creation and role allocation requests to Keystone, Nova and Cinder.
Need #1 : CPU performance based allocation and scheduling
As with all requests, there is a mixture of requirements and implementation. The needs are stated according to our current understanding. There may be alternative approaches or compromises which would address these needs in common with other user requirements. One of the aims of the Scientific Working group is to expose these ideas to other similar users, adapt them to meet the general community and work with the product working group, user committee and developers on an approach. Thus, the subsequent areas where CERN would be interested in improvements in the underlying software techologies.
The resource manager for the cloud in a high throughput/performance computing environment allocates resources based on performance rather than pure core count.
A user wants to request a processor of a particular minimum performance and is willing to have a larger reduction in his remaining quota.
A user wants to make a request for resources and then iterate according to how much performance related quota they have left to fill the available quota, e.g. give me a VM with less than a certain performance rating.
A resource manager would like to encourage the use of older resources which are often idle.
A quotas for slower and faster cores is currently the same (thus users create a VM, delete it if it is one of the slower type) so there is no incentive to use the slower cores.
As a resource manager preparing an accounting report, the faster cores should have a higher weight against the pledge to ensure continued treatment of slower cores.
The proposal is therefore to have an additional, optional quota on CPU units so that resource managers can allocate out total throughput rather than per core capacities.
The alternative approach of defining a number of flavors for each of the hardware types and quota. However, there are a number of drawbacks with this approach:
- The number of flavors to define would be significant (in CERN’s case, around 15-20 different hardware configurations multiplied by 4-5 sizes for small, medium, large, xlarge, …)
- The user experience impact would be significant as the user would have to iterate over the available flavors to find free capacity. For example, trying out m4.large first and finding the capacity was all used, then trying m3.large etc.
There is, as far as I know, no per-flavor quota. The specs have been discussed in some operator feedback sessions but the specification did not reach consensus.
Extendible resource tracking seems to be approaching the direction with ‘compute units’ (such as
here) as defined in the specification. Many parts of this are not yet implemented so it is not easy to see if it addresses the requirements.
Need #2 : Nested Quotas
As an experiment resource co-ordinator, it should be possible to re-allocate resources according to the priorities of the experiment without needing action by the administrators. Thus, moving quotas between projects which are managed by the experiment resource co-ordinators within the pledge allocated by the WLCG.
Nested keystone projects have been in the production release since Kilo. This gives the possibility for role definitions within the nested project structure.
The implementation of the nested quota function has been discussed within various summits for the past 3 years. The first implementation proposal,
Boson, was for a dedicated service for quota management. However, there were concerns raised by the PTLs on the impacts for performance and maintainability of this approach. The alternative of enhancing the quotas in each of the projects has been followed (such as
Nova). These implementations though have not advanced due to other concerns with quota management which are leading towards a common library,
delimiter, which is being discussed for Newton.
Need #3 : Spot Market
As a cloud provider, uncommitted resources should be made available at a lower cost but at a lower service level, such as pre-emption and termination at short notice. This mirrors the AWS spot market or the Google Pre-emptible instances. The benefits would be higher utilization of the resources and ability to provide elastic capacity for reserved instances by reducing the spot resources.
A draft specification for this functionality has been submitted along with the proposal which is currently being reviewed. An initial implementation of this functionality (called OpenStack Preemptible Instances Extension, or opie) will be made available soon on github following the work on Indigo Datacloud by IFCA. A demo video is available on YouTube.
Need #4 : Reducing quota below
utilization
As an experiment resource co-ordinator, quotas are under regular adjustment to meet the chosen priorities. Where a project has a lower priority but high current utilization, further resource usage should be blocked but existing resources not deleted since the user may still need to complete the processing on those VMs. The resource co-ordinator can then contact the user to encourage the appropriate resources to be deleted.
To achieve this function, one approach would be to allow the quota to be set below the current utilization in order to give the project administrator the time to identify the resources which would be best to be deleted in view of the reduced capacity.
Need #5 : Components without quota
As a cloud provider, some inventive users are storing significant quantities of data in the Glance image service. There is only a maximum size limit with no accumulated capacity leaves this service open to non-planned storage.
It is proposed to add quota functionality inside Glance for
- The total capacity of images stored in Glance
- The total capacity of snapshots stored in Glance
The number of images and snapshots would be an lower priority enhancement request since the service risk comes from the total capacity although the numbers could potentially also be abused.
Given that this is new functionality, it could also be a candidate for the first usage of the new delimiter library.
Need #6 : VM Expiration
As a private cloud provider, some VMs should be time limited to ensure that they are still required by their end users and automatically expire if there is no confirmation. Personal projects are often in this category as users will launch test instances but fail to delete them on completion of the test. These cases the users should be required to confirm that they will need the resources and that these are within their current allocated quota (Need #4).