)
This post dives deep into architecture, networking, storage and orchestration plus offers demos of lightning-fast upgrade and deployment.
The first part of the tutorial covers creating a continuous DevOps workflow and containers build.
Orchestrating containers for production?
Creating Docker containers for use in Docker Compose with host networking is easy for development and testing scenarios. However, if you want to run it in production, that’s when you will want scaling, balancing, orchestration, rolling updates, etc. Today, we consider Kubernetes the most suitable platform, because it provides the flexibility needed to run the containers application in production.
During prototyping we had to solve two things:
- Kubernetes architecture – how to deploy and operate Kubernetes cluster
- Service decomposition – how to separate OpenStack services into containers and what Kubernetes resources use for operations.
Kubernetes Architecture
The Kubernetes code base is moving very quickly. Every minor version contains fixes, features and sometimes deprecates existing functionality. We are currently working on the first robust packaging pipeline for Kubernetes and developed a new salt formula for deployment and manifests orchestration.
Network
Networking is usually most difficult part for every cloud solution. OpenStack Neutron plugins are the most controversial and crucial part of every discussion with a potential user. Kubernetes provides several plugins like Weave, Flannel, Calico, OpenContrail, OpenVSwitch, L2 bridging, etc.
We have comprehensive experience with OpenContrail as an overlay NFV & SDN most suitable for OpenStack Neutron. It is the de facto standard for our enterprise customers given that we believed we could use the same plugin for OpenStack as Kubernetes — even using the same instance of OpenContrail. However, after testing and deeper discussions, we realized that overlay is not suitable for underlay environment, which must be reliable and very simple. Running the same instance of OpenContrail for OpenStack Controllers increase the single point of failure. Alternatively, when we deployed extra OpenContrail cluster for Kubernetes, the product were Cassandra, Zookeeper, Kafka and Contrail services.
After some testing we found that Calico provides features what we need for underlay infrastructure – no overlay, simple, full L3, BGP support with ToR and no manual configuration of each node Docker0 bridge like Flannel. Another reason is that we do not require any multi-tenancy or security on network level; OpenStack control-plane services can be visible between each other. Calico does not have any complexity with regard to database clusters; it just uses a different ETCD instance. Standard overlay SDNs use different clusters like Cassandra, Zookeeper or Kafka.

In the end, we get OpenContrail on top of Calico, but it provides exactly what we require from production deployment.
- Underlay – Kubernetes + Calico
- Overlay – OpenStack + OpenContrail
Storage
Second decision point is building Kubernetes cluster. This point is tightly connected with the OpenStack services decomposition and specification, because we have to define storage share and persistency requirements.
We use three types of Kubernetes volumes:
- emptyDir – this type lives together with POD and container. It is not persistent and is suitable for temporary space like logs, tmp or signing dir.
- hostPath – volume mounts a file or directory from the host node’s filesystem into your pod. This is important for nova-compute /var/lib/nova/instances and libvirt cgroups, etc.
- Glusterfs – gluster has been already used in standard deployment for keystone fernet tokens or small glance image repositories. It is used share storage from controllers space. These two volumes are mounted into Keystone and Glance pods.
Logical Architecture
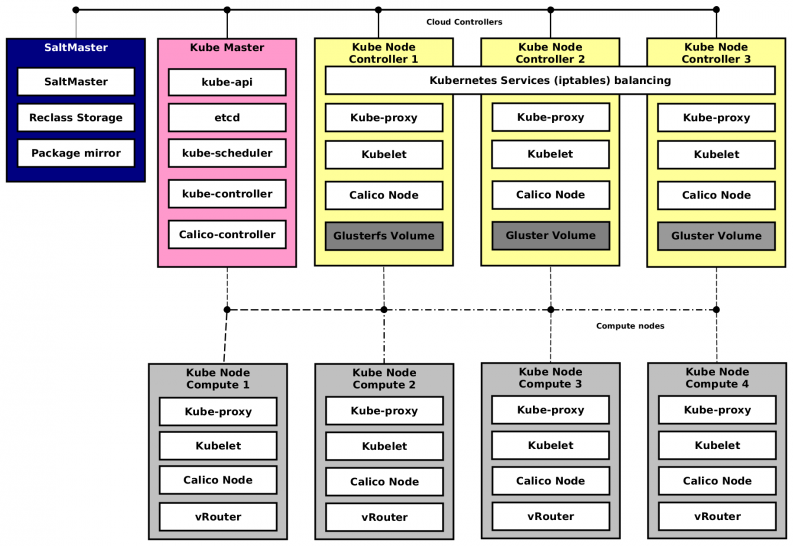
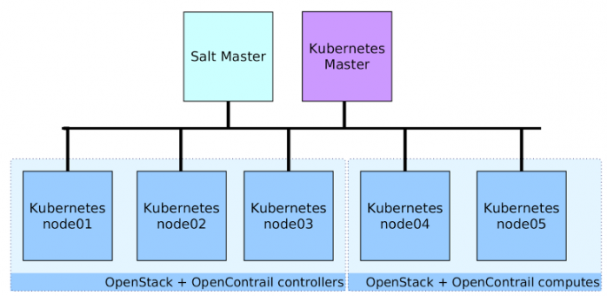
Following the diagram shows logical architecture for underlay Kubernetes cluster running on bare metal servers with Ubuntu 14.04 OS. On top of this Kubernetes cluster, we run OpenStack (including libvirt) and compute. All these services are installed directly to the bare metal servers by salt-formula-kubernetes.
SaltMaster contains metadata definition, packages and formulas for deployment both underlay and overlay.
- Kube Master – controller for Kubernetes and Calico. For production there must be at least three nodes with clustered ETCD. These nodes can be virtual machines as well.
- Kube Node Controller 1 – 3 – standard Kube nodes with Calico node dedicated for OpenStack control services. GlusterFS is deployed on local disks with two volumes for glance images and keystone fernet tokens.
- Kube Node Compute X – standard Kube nodes with Calico used for KVM hypervisors. This node contains OpenContrail vRouter with compiled kernel module. vRouter can be run in container too, but it is not suitable for production yet. This node will host nova-compute and libvirt containers, which will start OpenStack Virtual Machines.
OpenStack Service decomposition and specification
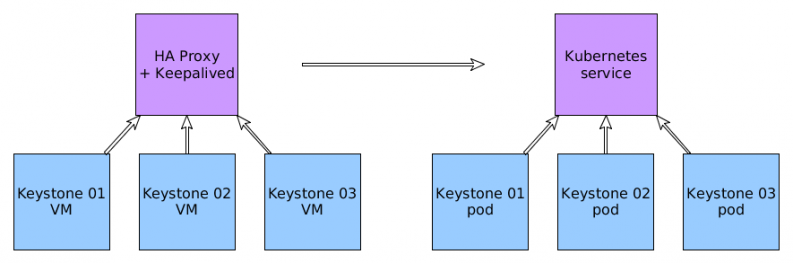
When Kubernetes underlay architecture is done, the next step is decomposition of OpenStack services. Transformation from the service oriented approach to the Kubernetes platform is shown in the following diagram. HAProxy with Keepalived (VIP address on VRRP) is replaced by built-in Kubernetes service load balancing. Virtual Machines are replaced by pods. Load balancing is implemented by a native service (iptables). This provides simplification of architecture and decrease potential components with errors. However, this cannot be used; advanced balancing methods are important for Mysql galera.
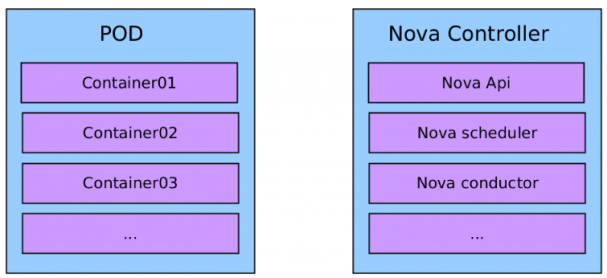
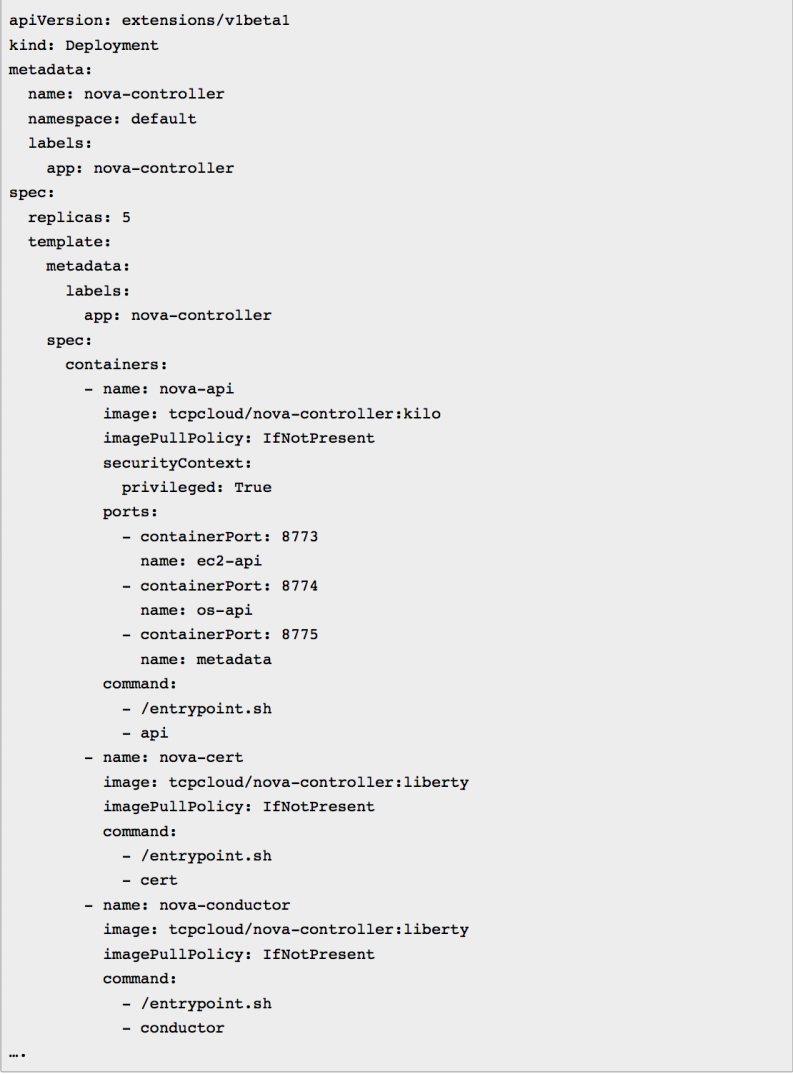
Sample OpenStack Nova service
This create container-base = pod = service =
_<deploy_name> / <service_name>–<role_name> : <version>
tcpcloud/nova-controller:kilo_
For the build, we need to determine between two parameters:
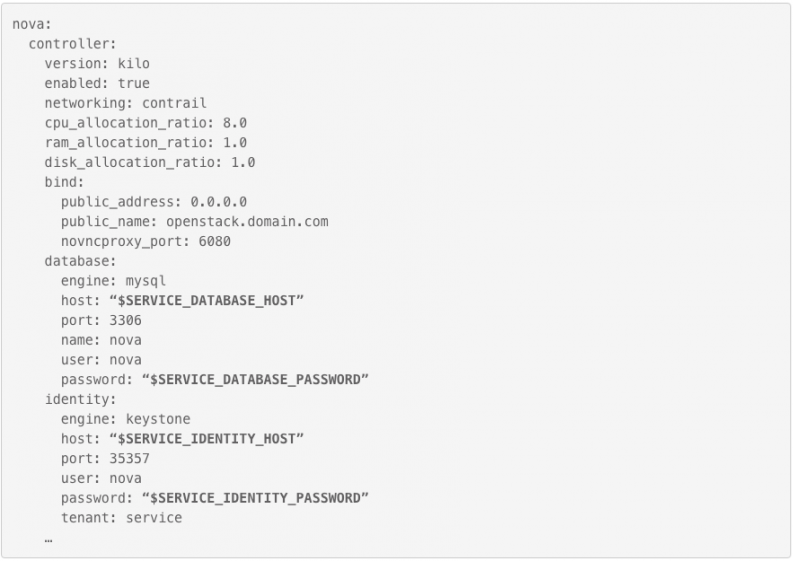
- Dynamic parameters – dynamic values depend on environment, replaced during container launching by entrypoint.sh (keystone_host, db_host, rabbit_host). Values comes from Kubernetes env or Docker Compose env values from manifest and etcd.
- Static parameters – pillar data pushed into container during its build. Pillar data in “salt” terminology are specific metadata. Hard coded in each container version inside of on-premise docker registry (cpu_overallocation_ratio, ram_allocation_ratio, token_engine, etc.).
Pillar definition snippet for this container build in reclass. Bold parameters represents dynamic parameters and rest values are static parameters.
Entrypoint.sh will replace dynamic parameters at configuration files by values provided by Kubernetes shared env variables.
e.g. $SERVICE_DATABASE_HOST -> 192.168.50.50
Kubernetes manifests will also define deployment resource and service endpoint. This is generated by salt-reclass (will be explained in next section about a single source of truth).
Kubernetes Deployment _<service_name>-<role_name>-deployment.yml
nova-controller-deployment.yml_
Kubernetes Service _<service_name>–<role_name>–svc.yml
nova-controller-svc.yml_

OpenStack on Kubernetes
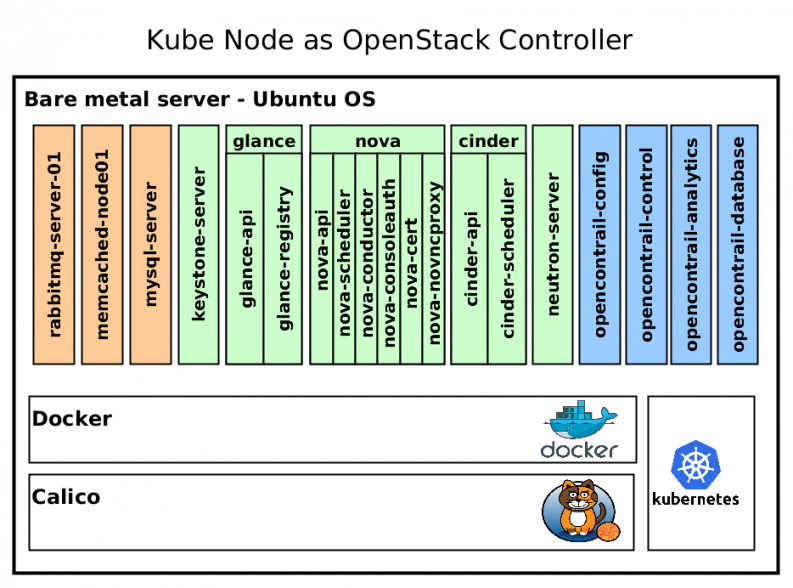
The figure shows a detailed schematic of the OpenStack compute and controller nodes to provide a deeper understanding of how it works.
Kube node as the OpenStack Controller runs kubelet, kube-proxy, Calico node, Docker as underlay services for management. On top of that, Kubernetes starts Docker containers defined by Kube deployment. OpenStack runs exactly the same as any other application. Rabbitmq runs as a pod with single container, but nova-controller pod contains six docker containers per nova service. Nova-controller docker image is same for these six containers, but starts different nova services on foreground.
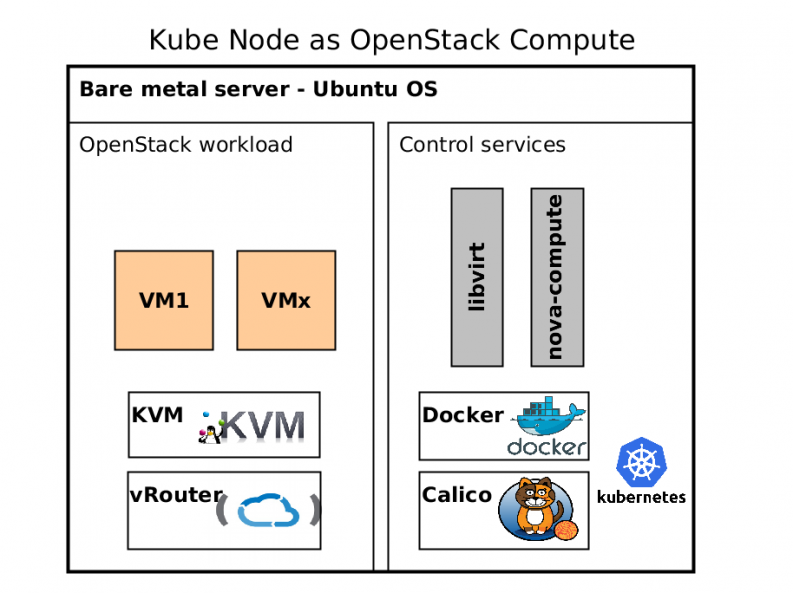
Kube Node as OpenStack compute is a little bit more difficult to explain. It runs the same components for underlay as a controller except Opencontrail vRouter. vRouter can be delivered by container as well, but it uses own kernel module, which must be compiled with a target kernel. Therefore, we decided to install vRouter in host OS.
Kubernetes orchestrates each compute pod with libvirt and nova-compute containers in privileged mode. These containers manage Virtual Machine workloads launched by Openstack.
It may be interesting to you that we are using two SDN solutions in a single host OS. The main difference is that we are using tcp connection to libvirt instead of unix socket.
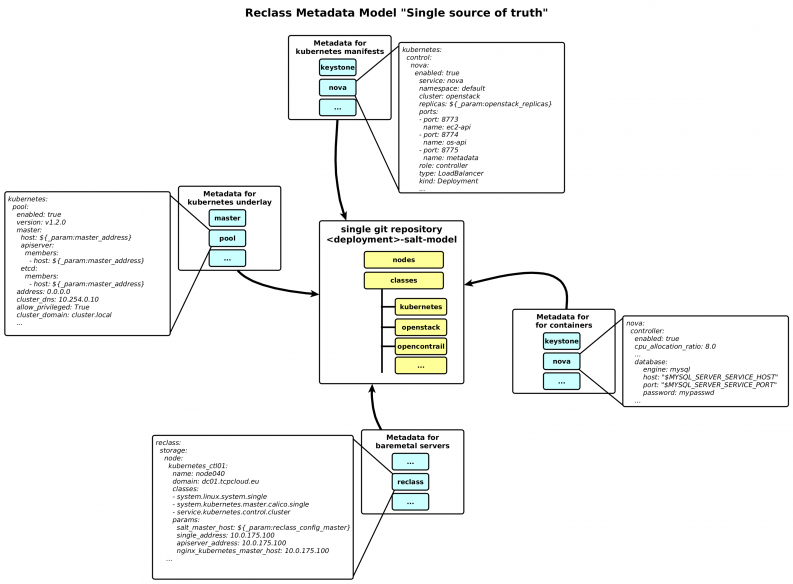
Single source of truth
Infrastructure-as-a-code is an approach, which reuse git workflow for doing changes in infrastructure. We treat infrastructure as a micro-services. Kubernetes as underlay together with Kubernetes manifest for OpenStack overlay must be contained in single repository as a “source of truth.” As we already mentioned, salt-formula-kubernetes provides not only deployment but Kubernetes manifests as well. This repository also contains definition for the Docker image build process.
The following diagram shows a single git repository generated per deployment, which contains metadata for all components–including bare metal infrastructure provisioning, Kubernetes and Calico control services, Docker image building metadata and Kubernetes manifests for OpenStack control services. It’s set of YAML-structured files with classes and roles.
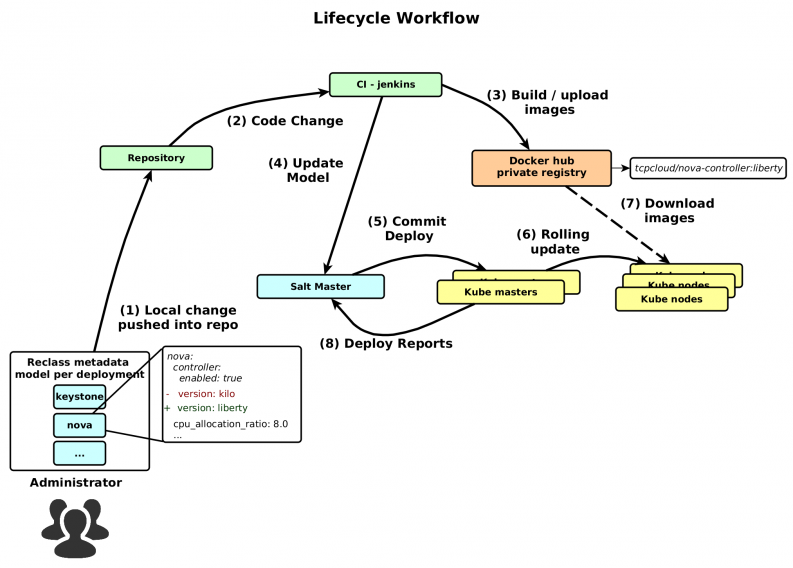
The following figure shows lifecycle workflow of configuration change in OpenStack. This demonstrates the scenario of upgrading from Kilo to Liberty.
- Administrator clones git repository with reclass metadata model. Then change version from Kilo to Liberty and push back.
- Post hook action notifies CI system about this change, which automatically starts jobs.
- It builds and upload a new version of nova-controller docker image into private registry.
- In the meantime, another job updates metadata model directly on the salt master server.
- Next step depends on manual action of administrator. He has to call deploy action from salt master. It updates Kubernetes manifests on master.
- Next, apply a new version of manifest, which trigger deployment rolling update build in Kubernetes.
- During the rolling update, Kubelet automatically downloads new images from registry.
- A final report is sent back to salt master for administrator verification.
Now let’s show how this concept looks live. The next section contains several videos with live demos from the environment.
Upgrade OpenStack in two minutes?
We created the following simple deployment for a showcase scenario. We deployed this in OpenStack Days Budapest and Prague. We used six bare metal servers for this showcase:
- Salt Master – single source of truth and orchestration
- Kubernetes master – single kube controller for cluster with manifests.
- Kube node as OpenStack Controller – three nodes for running control services.
- Kube node as OpenStack Compute – two nodes for running nova-compute, libvirt and OpenContrail vRouter.
In this video from OpenStack Day Prague, we explain the journey behind this solution and demonstrate a complete OpenStack Kilo deployment, scaling and then upgrading to Liberty.
In the next video, we show OpenStack Kilo deployment on Kubernetes cluster in three minutes. After, we show how easily it can be scaled on three instances for High Availability. The last part contains booting of two instances and a live upgrade of OpenStack without any packet loss between VMs. Everything can be done in 10 minutes, which shows how efficient running OpenStack in containers is.
The last video is from the deep dive session, Kubernetes on OpenStack. Here we show the architecture and technical design.
Conclusion
We proved how easily everything that was built and developed in the last three years can be reused to provide a new enterprise deployment workflow. There still must be testing done on use cases however, this method is really suitable for CI/CD OpenStack pipelines.
If you are interested in learning more, please join the regular IRC OpenStack-salt meetings or send us feedback.
This post first appeared on tcp cloud’s blog. Superuser is always interested in community content, email: [email protected]
Cover Photo // CC BY NC










