)
Container schedulers like Kubernetes, Swarm, Mesos, Rancher and others have become a very hot topic in cloud infrastructure discussions. They promise a level of abstraction over infrastructure that reduces operational complexity and improves interoperability by hiding many of the differences between different platforms.
Of these benefits, the idea of integrated mechanisms for upgrades and high availability is especially attractive; however, these features are not free. They require applications be adapted for the platforms.
With such high potential benefits, it’s no surprise that some in the OpenStack community want to use these platforms to also operate OpenStack. In my opinion, this confusing fusion of the technologies is inevitable because of the rapidly expanding footprint of container schedulers.
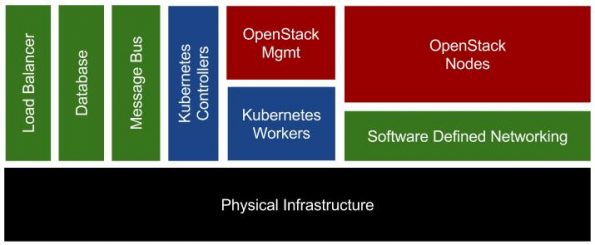
For the Barcelona Summit, I put together a pragmatic review of the pros and cons of this approach including an iterative path forward. This review included the architecture diagram in this post.
Many people were glad to see a balanced operations focused presentation.
Several points generated discussion:
First was the distinction between plain old container installs (“POCI”) and this more automated approach. The key element being use of immutable 12-factor designs.
Next were the OpenStack services that can be more easily adapted to this design and how to evaluate services that can easily survive IP movement and mid-transaction termination.
We also discussed broader internal refactoring that would be required. Happily, these items would make OpenStack more durable and upgradable in all operational scenarios.
Not everyone agrees with my iterative and cautious recommendation. For example, engineers from Mirantis have been very vocal in the community promoting this approach — dubbing it “Evolve or Die” — with support from CoreOS and Intel (see also their “Lessons Learned” session from Barcelona and the earlier “Stakanetes” intro).
They have been able to run all services in containers including the Nova Compute, Libvirt and agents by pinning containers to specific hosts. This approach does provide benefit of using Kubernetes to manage the version of containers running OpenStack components. However, much work remains to ensure that it’s operationally pragmatic.
Overall, I believe that declarations of broad success are overstated due to marketing pressures to show progress. More importantly, I believe that the rationale for adding this complexity into the environment not well developed. It is important to note that the Kubernetes community itself is still working on critical operational details like HA, security and upgrades.
That does not mean that I’m giving up on the effort! In fact, I’m very excited to collaborate on taking steps towards a more integrated solution. The RackN team has been pulling together many of the control elements that are required to build the integration (check out our Kubernetes demo).
Right now, I’m refining my “Will it Blend” talk based on feedback and will be taking it on the road to the Mountain OpenStack Days Salt Lake City, the first week of December.
I’d love to hear your thoughts about the presentation, the Kubernetes underlay approach and making OpenStack operationally robust in general.
Rob Hirschfeld has been active in the OpenStack community since 2012. He’s served as a Board member and is a tireless champion of interoperability. You can also find him on Twitter or on his blog.
Superuser is always interested in community content, get in touch at [email protected].










