We have recently made the Container-Engine-as-a-Service (Magnum) available in production at CERN as part of the CERN IT department services for the LHC experiments and other CERN communities. This gives the OpenStack cloud users Kubernetes, Mesos and Docker Swarm on demand within the accounting, quota and project permissions structures already implemented for virtual machines.
We shared the latest news on the service with the CERN technical staff (link). This is the follow up on the tests presented at the OpenStack Barcelona (link) and covered in the blog from IBM. The work has been helped by collaborations with Rackspace in the framework of the CERN openlab and the European Union Horizon 2020 Indigo Datacloud project.
Performance
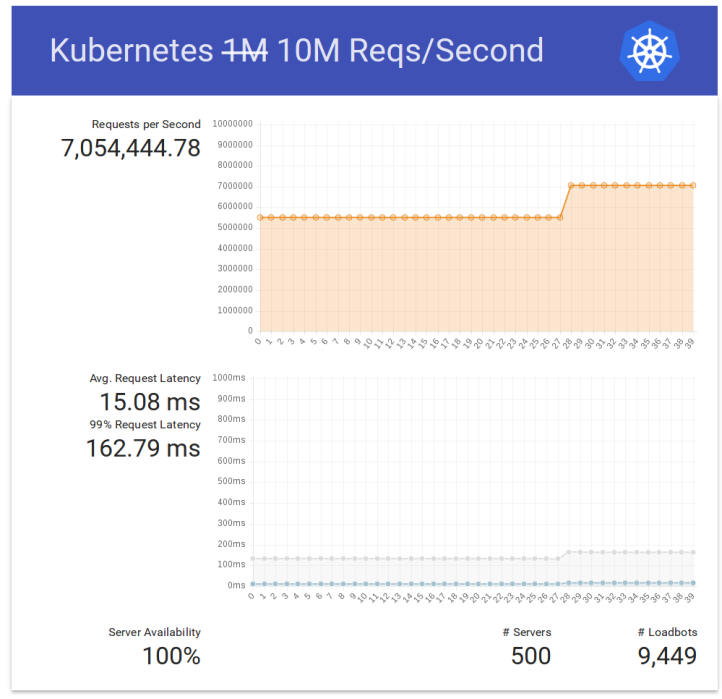
|
Cluster Size (Nodes)
|
Concurrency
|
Deployment Time (min)
|
|
2
|
50
|
2.5
|
|
16
|
10
|
4
|
|
32
|
10
|
4
|
|
128
|
5
|
5.5
|
|
512
|
1
|
14
|
|
1000
|
1
|
23
|
Storage
With the LHC producing nearly 50PB this year, High Energy Physics has some custom storage technologies for specific purposes, EOS for physics data, CVMFS for read-only, highly replicated storage such as applications.
One of the features of providing a private cloud service to the CERN users is to combine the functionality of open source community software such as OpenStack with the specific needs for high energy physics. For these to work, some careful driver work is needed to ensure appropriate access while ensuring user rights. In particular,
- EOS provides a disk-based storage system providing high-capacity and low-latency access for users at CERN. Typical use cases are where scientists are analysing data from the experiments.
- CVMFS is used for a scalable, reliable and low-maintenance for read-only data such as software.
- HDFS for long term archiving of data using Hadoop which uses an HDFS driver within the container. HDFS works in user space, so no particular integration was required to use it from inside (unprivileged) containers
- Cinder provides additional disk space using volumes if the basic flavor does not have sufficient. This Cinder integration is offered by upstream Magnum, and work was done in the last OpenStack cycle to improve security by adding support for Keystone trusts.
Service model
- The end user launches a container engine with their specifications but they rely on the IT department to maintain the engine availability. This implies that the VMs running the container engine are not accessible to the end user.
- The end user launches the engine within a project that they administer. While the IT department maintains the templates and basic functions such as the Fedora Atomic images, the end user is in control of the upgrades and availability.
- A variation of option 2., where the nodes running containers are reachable and managed by the end user, but the container engine master nodes are managed by the IT department. This is similar to the current offer from the Google Container Engine and requires some coordination and policies regarding upgrades
Applications
Ongoing work
- Cluster upgrades will allow us to upgrade the container software. Examples of this would be a new version of Fedora Atomic, Docker or the container engine. With a load balancer, this can be performed without downtime (spec)
- Heterogeneous cluster support will allow nodes to have different flavors (cpu vs gpu, different i/o patterns, different AZs for improved failure scenarios). This is done by splitting the cluster nodes into node groups (blueprint)
- Cluster monitoring to deploy Prometheus and cAdvisor with Grafana dashboards for easy monitoring of a Magnum cluster (blueprint).
References
- End user documentation for containers on the CERN cloud at http://clouddocs.web.cern.ch/clouddocs/containers/index.html
- CERN IT department information is at http://cern.ch/it.
- CERN openlab Rackspace collaboration on container presentations are listed here.
- Indigo Datacloud project details are here.
This post first appeared on the OpenStack in Production blog. Superuser is always interested in community content, email: [email protected].
Cover Photo // CC BY NC
- Containers on the CERN Cloud - February 17, 2017
- OpenStack in production: CERN’s cloud in Kilo - February 1, 2016










